











You are browsing documentation for an older version. See the latest documentation here.
About service meshes
Service Mesh is a technology pattern that implements a better way to implement modern networking and connectivity among the different services that make up an application. While it is commonly used in the context of microservices, it can be used to improve connectivity among every architecture and on every platform like VMs and containers.
Reliable service connectivity is a pre-requisite for every modern digital application. Transitioning to microservices - and to the Cloud - can be disastrous if network connectivity is not taken care of, and this is exactly why Kong Mesh was built.
When a service wants to communicate to another service over the network - like a monolith talking to a database or a microservices talking to another microservice - by default the connectivity among them is unreliable: the network can be slow, it is unsecure by default, and by default of those network requests are not being logged anywhere in case we need to debug an error.
In order to implement some of these functionalities, we have two options:
- We extend our applications ourselves in order to address these concerns. Over time this creates technical debt, and yet more code to maintain in addition to the business logic that our application is delivering to the end-user. It also creates fragmentation and security issues as more teams try to address the same concerns on different technology stacks.
- We delegate the network management to something else that does it for us. Like - for instance - an out-of-process proxy that runs on the same underlying host. Sure, we have to deal with a slightly increased latency between our services and the local proxy, but the benefits are so high that it quickly becomes irrelevant. This proxy - as we will learn later - is called sidecar proxy and sits on the data plane of our requests.
In the latter scenario - when delegating network management to another process - we are going to be having a data plane proxy for each replica of every service. This is required so we can tolerate a failure to one of the proxies without affecting other replicas, and also because we can assign an identity to each proxy and therefore to each replica of our services. It is also important that the data plane proxy is very lightweight since we are going to be having many instances running.
While having data plane proxies deployed alongside our services helps with the network concerns we have described earlier, it introduces a new problem: managing so many data plane proxies becomes challenging, and when we want to update our network policies we certainly don’t want to manually reconfigure each one of them. In short, we need a source of truth that can collect all of our configuration - segmented by service or other properties - and then push the configuration to the individual data plane proxies whenever required. This component is called the control plane: it controls the proxies and - unlike the proxies - it doesn’t sit on the execution path of the service traffic.
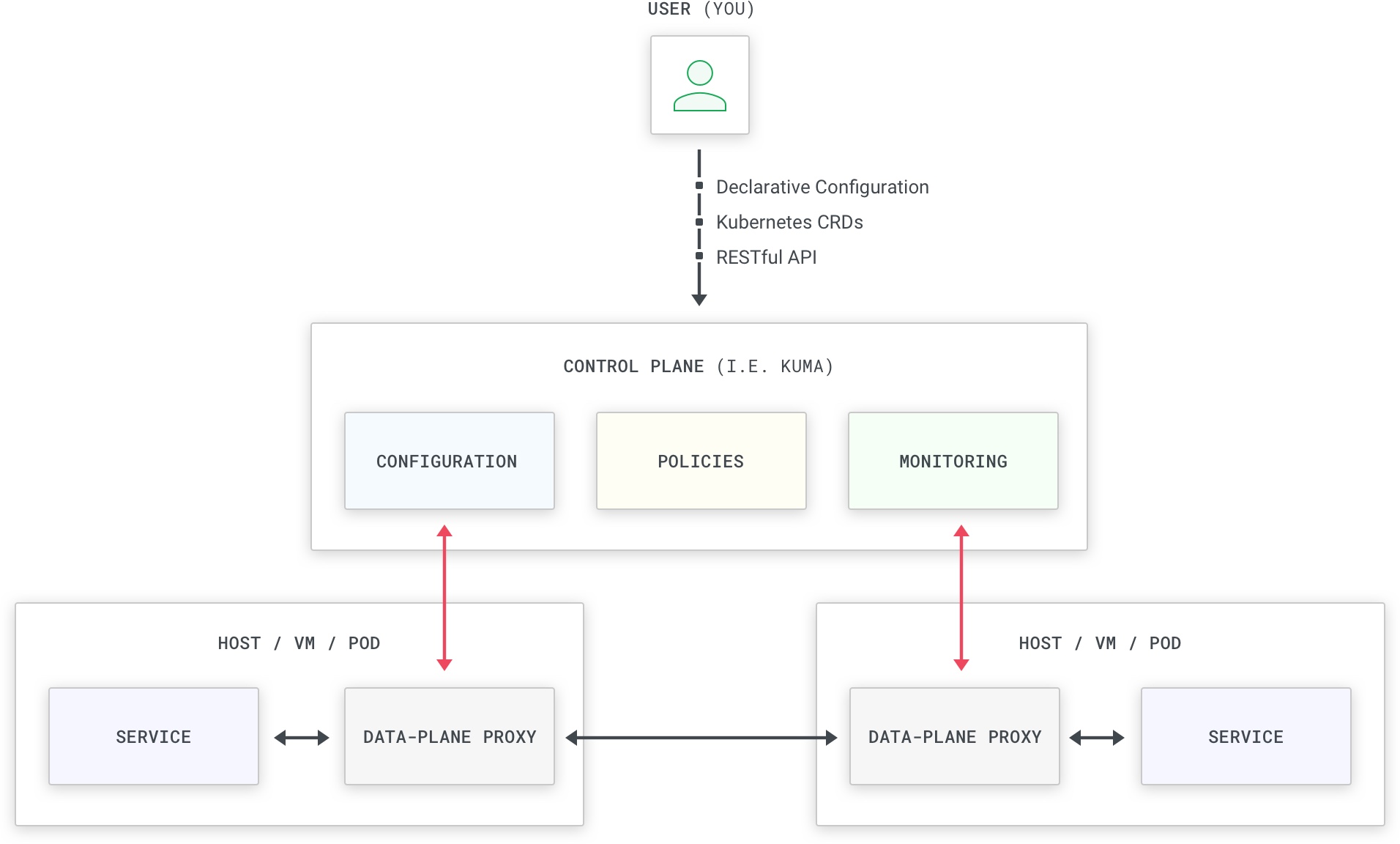
We are going to be having many proxies connected to the control plane in order to always propagate the latest configuration, while simultaneously processing the service-to-service traffic among our infrastructure. Kong Mesh is a control plane (and it is being shipped in a kuma-cp binary) while Envoy is a data plane proxy (shipped as an envoy binary). When using Kong Mesh we don’t have to worry about learning to use Envoy, because Kong Mesh abstracts away that complexity by bundling Envoy into another binary called kuma-dp (kuma-dp under the hood will invoke the envoy binary but that complexity is hidden from you, the end user of Kong Mesh).
Service Mesh does not introduce new concerns or use-cases: it addresses a concern that we are already taking care of (usually by writing more code, if we are doing anything at all): dealing with the connectivity in our network.
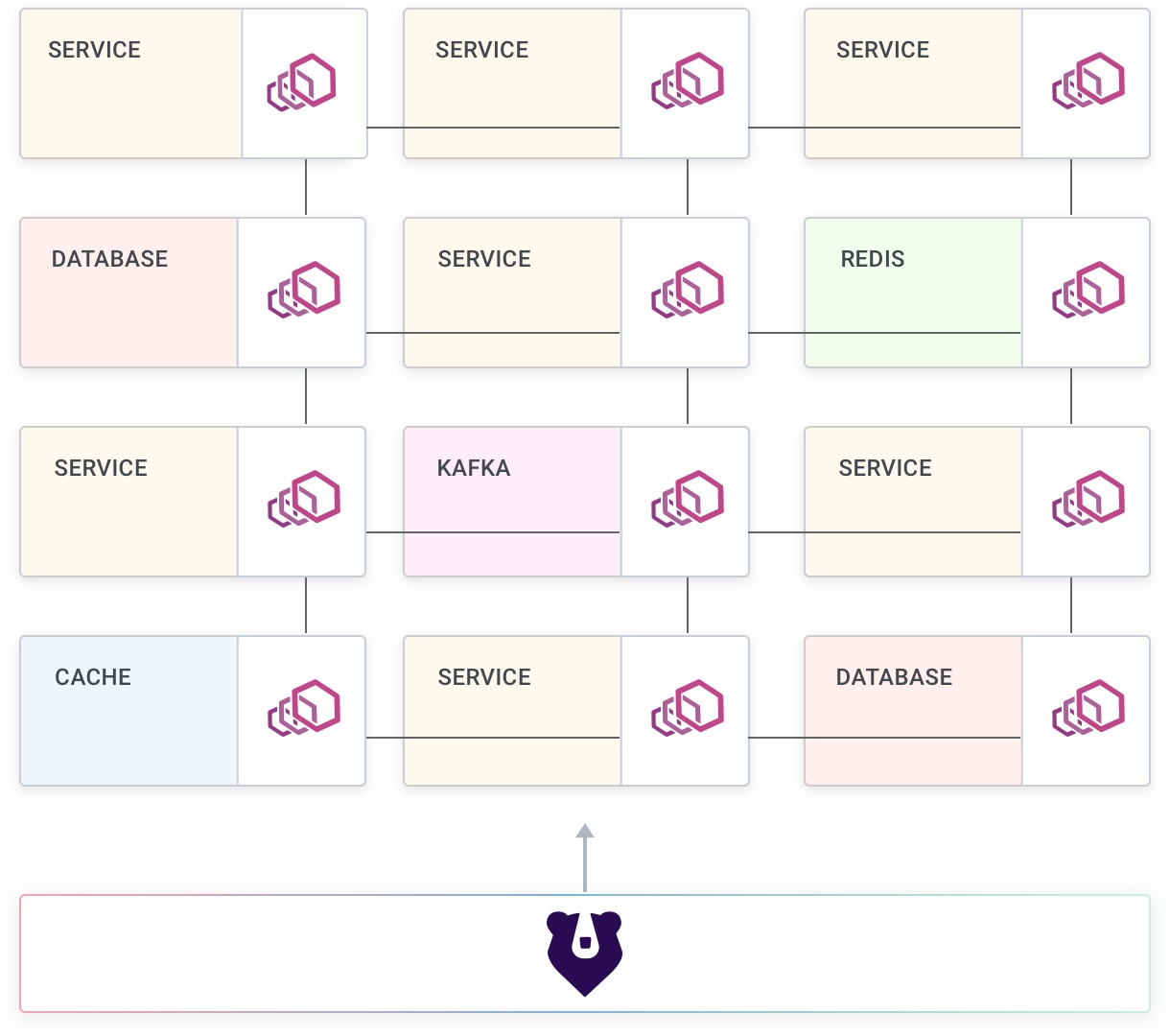
As we will learn, Kong Mesh takes care of these concerns so that we don’t have to worry about the network, and in turn making our applications more reliable.